Digital Humanities research projects produce a variety of digital artefacts that need to be preserved because they constitute a central part of the employed methods and/or the actual research output. These artefacts include, but are not limited to:
– digitised sources
– databases
– user interfaces
– project websites
– interactive notebooks
– interactive visualisations
– data queries
– analysis workflows and results
– processing pipelines (e.g. OCR workflows, entity extraction)
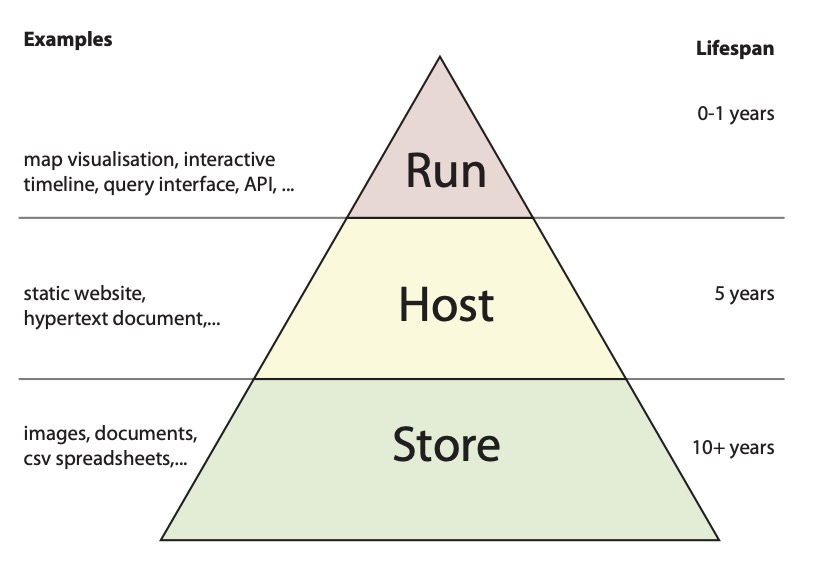
The challenges for data management and long term preservation of such digital artefacts differ based on the technical requirements of the artefacts themselves and the requirements of the individual research project in terms of publication. Rather than defining a use case for each type of artefact and publication scenario, we propose to think of them in three general categories:
– artefacts that need to be stored
– artefacts that need to be hosted
– artefacts that need to be run
Artefacts that can be stored include images, documents, compressed archives, in short, any individual or collection of digital files.
Artefacts that need to be hosted include documents, images or complete (static) websites that are stored and made be available and accessible via a web browser.
Artefacts that need to be run include dynamic websites that retrieve content from a database, or interactive visualisations that run in a user’s browser; artefacts that are not only hosted but require code to be executed in order to be used.
The reason we make this discrimination here is due to the different amount of maintenance the artefacts require and, as a result, the ease with which they can be preserved after a Digital Humanities project has ended. A properly stored digital artefact is likely to still be usable and accessible in 10 years time. An artefact that needs to be run may become unusable in a matter of months. Nevertheless, we may still want to make use of cutting edge technology in Digital Humanities research
To strike this balance we propose the strategy of Graceful Degradation. The term is borrowed from web development where it refers to the preservation of basic website functionalities in the absence of certain (advanced) technological requirements. Employed to the store/host/run pyramid introduced above, this means creating artefacts that don’t exclusively reside in the top, but are built on a foundation that can be stored and hosted, keeping the digital artefact accessible once the top of the pyramid has eroded.
Strategy
The reason we make this discrimination between stored, hosted and running artefacts is due to the different amount of maintenance they require and, as a result, the ease with which they can be preserved after a digital research project has ended. While a properly stored digital artefact is likely to still be usable and accessible in 10 years, an artefact that needs to be run may become unusable in a matter of months.
Our central strategy for dealing with digital projects and research data is to produce artefacts that can be gracefully degraded to the lower and more sustainable parts of the store/host/run pyramid. This does not exclude the use of the latest technology or creating interactive research outputs that can only occupy the top of the pyramid, but to ensure that the foundation used to create it is available in the proper format.
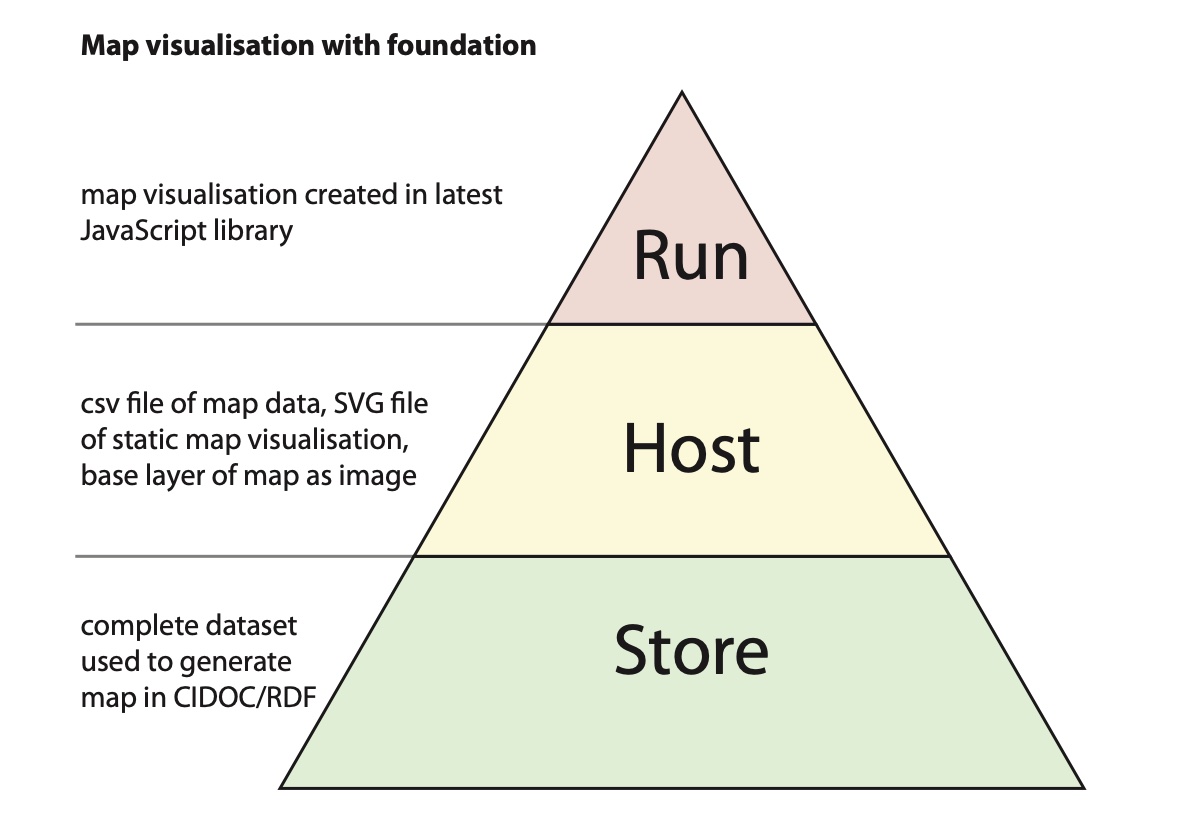
The diagrams below illustrates an example of an interactive map visualisation. While it is possible to produce a visualisation purely as a runnable artefact, building it on top of a foundation of reusable and static content means that both the raw data remains available once the visualisation breaks and that the visualisation can be recreated or enhanced using future technologies.

Examples
STORING digital artefacts
Artefacts that can be stored are arguably the most trivial in this context and therefore often do not receive much consideration within research projects. Nevertheless there are some practices that can make dealing with them during and after a research project easier, which are described in the following.
While a project is ongoing
Make use of a cloud storage solution to store your files during your research project. This allows you to:
– Share project-specific files with members of your research group and other collaborators. Avoid sharing files via emails because you and your collaborators may easily lose sight of the latest version of a document or create multiple conflicting copies.
– Have a backup. In case your personal computer breaks down or gets stolen, you still have access to all your data
– Have version control. Most cloud storage solutions allow you to go back in time and access earlier version of your files, in case you want to see what changed or go back to an earlier draft.
Use non-proprietary file formats. Some file types can only be opened using specific software, such as Adobe Photoshop files, or files produced by specialised GIS software. Your collaborators may not have access to such software. Most importantly, files may become unreadable when software becomes unavailable or ceases to run on future systems. If you need to rely on specialised software be sure to also export copies of your file in non-proprietary formats.
When a project has ended
Archiving digital artefacts that can be stored is relatively straightforward. Depending on the kind of artefacts and whether or not you want your artefacts to be available to others, there are different solutions available:
For public archiving you can make use of the DARIAH Repository. The platform allows you to store your data for others to download and supplies a permanent ID with which the data can be cited and accessed.
HOSTING digital artefacts
Hosting digital artefacts means storing them in a way that they can be viewed in a web browser. Strictly speaking, files stored in the DARIAH Repository are hosted as well, but they are meant to be downloaded, not viewed directly in the browser. A hosted artefact can be accessed via a URL and ideally this URL should not change over time so it can be cited in books or papers.
A typical hosted artefact can be a project website that does not have a database backend, i.e. a static website that allows you to navigate between pages, view images, etc.
Digital and digitised sources, such as scanned documents, books, photographs, movies, etc. for which you have obtained the rights for them to be published, or which are in the public domain, can be stored permanently public repositories such as Wikimedia Commons or the Internet Archive.1 Static websites need to be hosted on servers that remain accessible and running in the foreseeable future. If at all possible, these ideally are servers that one or one’s institution has control over. Free services, such as GitHub pages may be a convenient solution for publishing custom websites, however there is no guarantee that the service will not be discontinued eventually.
RUNNING digital artefacts
Digital artefacts that run need to be stored and hosted, and additionally need to be executed either on the computer on which they are stored (the server) or on the computers on which they are viewed (the client). Examples include database interfaces that lets user perform custom queries, interactive visualisations such as maps, timelines or graphs, pipelines that retrieve and process data from different sources, etc.
This type of digital artefact is the most difficult for long term preservation and accessibility. Server-run artefacts may stop working when the system is upgraded, or they may break due to errors in the software or attacks. Client-run artefacts rely on certain software environments on a user’s computer, which may change in the future.2 Pipelines that rely on external services may break when those services become unavailable or change.
In most instances this type of content can be hosted and expected to be running for at least a year after its creation. Effectively however, running digital artefacts need to be constantly maintained and should not be assumed to still be working after a project has ended.
Due to the fragile nature of this type of content it should always be treated as ephemeral. This may be counter-intuitive as there are many examples of interactive digital content created on the web years ago that are still running. However, behind the scenes, this content is either constantly maintained and updated, or their creators happen to pick technology that still works today.
In order to preserve this type of artefacts they may be reproduced in formats that can be stored or hosted. Interactive databases can be converted to static ones, stripping away the custom query capability but keeping its content accessible. Visualisations can be captured in videos as screencasts. Pipelines can be pre-run with different content and in-between steps stored as separate artefacts. Reproducing artefacts in this way inevitably removes some of their interactivity, but it guarantees that content remains accessible, albeit in a slightly reduced way.
- Given the relative novelty of digital technologies we of course cannot foresee what ‘permanent’ means in this context. .
- Most current computers are unable to display Flash content, a de-facto standard for content creation a few years ago, rendering content that may be still hosted effectively inaccessible.
About this post: this is an adapted version of a policy document on dealing with Digital Humanities research artefacts I wrote in 2019 for internal use for the Max Planck Institute for the History of Science. Based on this, I proposed a paper for the DH2020 conference. Unfortunately, the proposal was declined, which is why I never wrote the final paper. Due to recent interest in the Store/Run/Host framework by colleagues and collaborators, I decided to publish this version here.