Why not Linked Data, asks a fellow Tweeter and Tate’s web architect Rich Barrett-Small justifies their move to GitHub with it being the most time- and cost-effective solution to get the data out there – for now.
Yes, SPARQL endpoints are the weapon of choice these days, but what’s wrong with using GitHub? It’s an incredibly versatile platform by far not limited to programmers, but equally useful for thesis writing or democracy.
What’s great about using GitHub, as opposed to APIs, is that it doesn’t only give you access to the data, it gives you the data. Maybe I’m old school, but I do like having real files on my hard drive, as opposed to it all being locked off in a cloud. And it’s still possible to keep the data updated, by syncing it with the original repository.
But enough about pros and cons of technical details, let’s have a look at what Tate offers.
The dataset contains the complete records of all the artists and artworks in the collection, excluding images, which still need to be accessed online. The dataset comes in two flavours: two CSV files containing the artists and artworks and a gazillion of text files containing all the records in JSON format. The JSON data is richer, because it allows to store the kind of data a table is unable to hold – most notably – a list of subjects associated with the record organised in a range of topics (“people”, “natural phenomena”, “emotions, concepts and ideas”, etc.).
The dataset is very rich and still of a manageable size, so I will definitely do something with it. As a first step, I wanted to get an overview of the distribution of the collection in time. Most of the collection is from around 1800 and a considerable part of it is from 1960 and later.
I wanted to get a picture of the most important artists in the collection and their position in time. So I made a sketch in d3 which plots the artists as circles along a time axis and sizes them proportionally to the amount of works they have in the collection. This was the result:
 One big balloon and a lot of awful tiny dots. I did not put a timescale but the balloon was positioned around 1800. So it turns out that not only is a large chunk of the collection from the same time, it also is by the same man: William Turner! (well that didn’t really come as a surprise).
I imported the CSV data into an SQL table, so I could easily extract all that is Turner and all that is not Turner from the collection. Below is Excel’s rendition of the result. Everything that’s Turner is in red, everything that’s not Turner is blue.
One big balloon and a lot of awful tiny dots. I did not put a timescale but the balloon was positioned around 1800. So it turns out that not only is a large chunk of the collection from the same time, it also is by the same man: William Turner! (well that didn’t really come as a surprise).
I imported the CSV data into an SQL table, so I could easily extract all that is Turner and all that is not Turner from the collection. Below is Excel’s rendition of the result. Everything that’s Turner is in red, everything that’s not Turner is blue.
 Of course this screams for a pie chart. It turns out, the majority of Tate’s collection is Turner:
Of course this screams for a pie chart. It turns out, the majority of Tate’s collection is Turner:
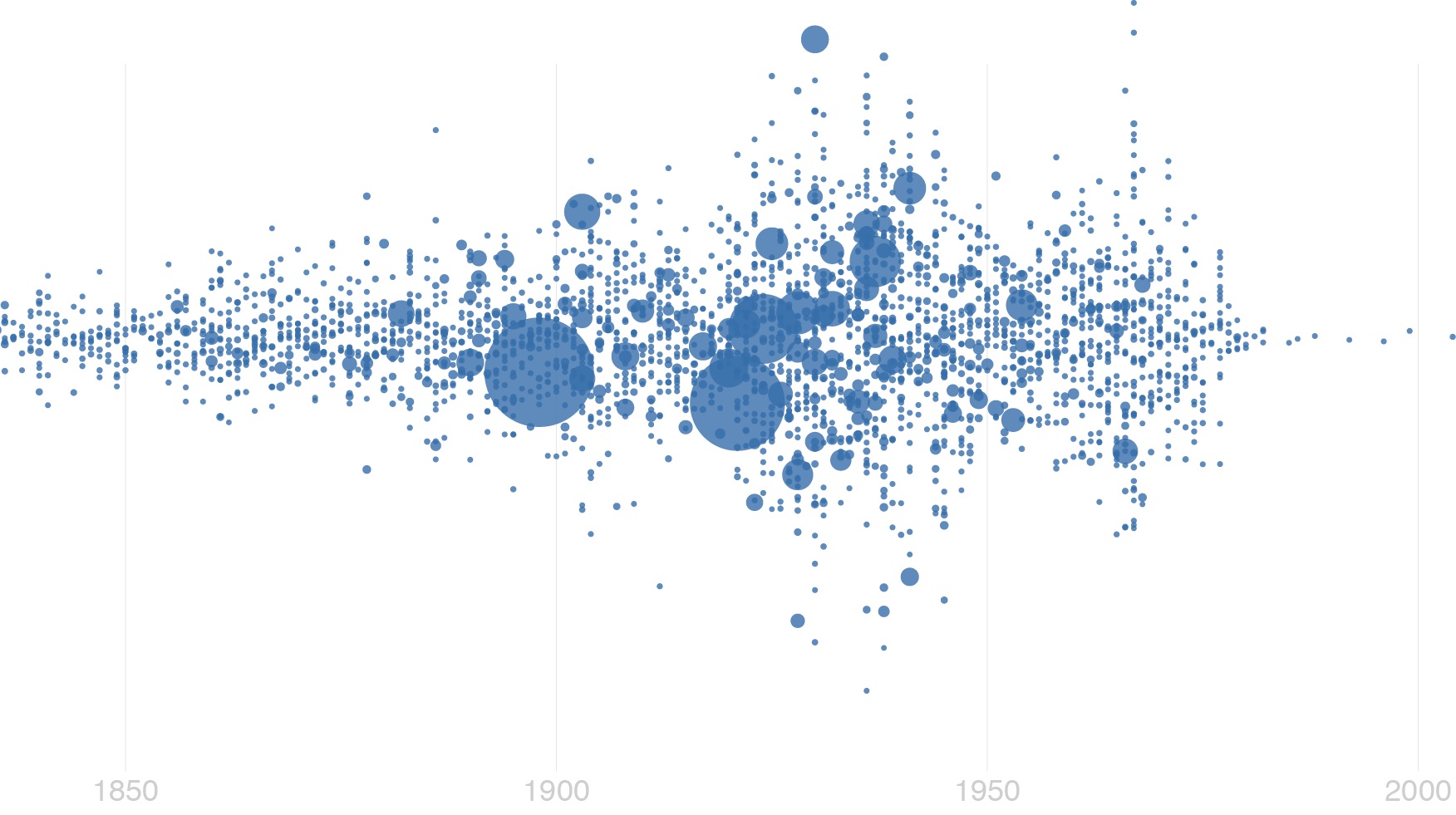
 I decided that’s enough about Turner for now and removed all that’s Turner from the data. I wanted to look at the collection without this extreme case. Now at least my bubble visualisation had some depth.
I decided that’s enough about Turner for now and removed all that’s Turner from the data. I wanted to look at the collection without this extreme case. Now at least my bubble visualisation had some depth.
 Here they all are. Every bubble represents an artist, horizontally positioned based on year of birth and sized proportionally to the amount of works they have in the collection. They are vertically spread out depending on how many artists are born in the same year, but the positioning does not carry any information. The top artists (excluding Turner) now are:
Here they all are. Every bubble represents an artist, horizontally positioned based on year of birth and sized proportionally to the amount of works they have in the collection. They are vertically spread out depending on how many artists are born in the same year, but the positioning does not carry any information. The top artists (excluding Turner) now are:
| Name | Born | # works |
|---|---|---|
| Jones, George | 1786 | 1046 |
| Moore, Henry, OM, CH | 1898 | 623 |
| Daniell, William | 1760 | 612 |
| Beuys, Joseph | 1921 | 578 |
| British (?) School | 388 | |
| Paolozzi, Sir Eduardo | 1924 | 385 |
| Flaxman, John | 1755 | 287 |
| Phillips, Esq Tom | 1937 | 274 |
| Warhol, Andy | 1928 | 272 |
| Constable, John | 1776 | 249 |
I plugged the artwork data into the same visualisation, but plotting every artwork at the same size. The resulting picture looked as expected, except for a strange peak in the year 1814. Has the Tate purchased an anomaly large amount of paintings from 1814?
 This vertical stripe of data remained even after I removed all the mistakes I encountered on my side (misinterpreted dates, plotting missing dates, etc.), so I wondered where this comes from. I had to get back at the raw data to find an answer. It turns out all these paintings are by William Daniell and in fact their date isn’t known. So why did they appear in 1814?
The Tate collection, as most others, use two fields for storing the date: one as text and one as number (year). The text field would be usually displayed when accessing the collection as it can contain more fine grained information than just a number (e.g. ‘ca. 1814’, ‘around 1800’ etc.). But when this data is visualised, the dates need to be present in a machine readable format. I have encountered a few cases where the descriptive dates and the numerical dates do not match. Often it is because there as an error in the automatic conversion from the ‘human’ to the ‘machine’ date.
I’m not sure why in this case the date appears as 1814. It might be a compromise because, of course, the date is not completely unknown if, such as in this case, the lifetime of its painter is known (1769?1837). So 1814 might just be a likely date, but there is no way of recording likelihood.
As a last tryout I combined the two bubble diagrams and tried connecting the artworks to their creator. A black line links the artist to the artwork. Again, Turner is left out of this picture (sorry).
I expected all artworks to be connected to an artwork but it seems that most records remain unconnected. This may very likely be a mistake on my side, I’ll have to look into this.
That’s all for now, but I hope to be able to play around more with the Tate collection very soon.
This vertical stripe of data remained even after I removed all the mistakes I encountered on my side (misinterpreted dates, plotting missing dates, etc.), so I wondered where this comes from. I had to get back at the raw data to find an answer. It turns out all these paintings are by William Daniell and in fact their date isn’t known. So why did they appear in 1814?
The Tate collection, as most others, use two fields for storing the date: one as text and one as number (year). The text field would be usually displayed when accessing the collection as it can contain more fine grained information than just a number (e.g. ‘ca. 1814’, ‘around 1800’ etc.). But when this data is visualised, the dates need to be present in a machine readable format. I have encountered a few cases where the descriptive dates and the numerical dates do not match. Often it is because there as an error in the automatic conversion from the ‘human’ to the ‘machine’ date.
I’m not sure why in this case the date appears as 1814. It might be a compromise because, of course, the date is not completely unknown if, such as in this case, the lifetime of its painter is known (1769?1837). So 1814 might just be a likely date, but there is no way of recording likelihood.
As a last tryout I combined the two bubble diagrams and tried connecting the artworks to their creator. A black line links the artist to the artwork. Again, Turner is left out of this picture (sorry).
I expected all artworks to be connected to an artwork but it seems that most records remain unconnected. This may very likely be a mistake on my side, I’ll have to look into this.
That’s all for now, but I hope to be able to play around more with the Tate collection very soon.
